Neural Capture of Animatable 3D Human from Monocular Video
Abstract
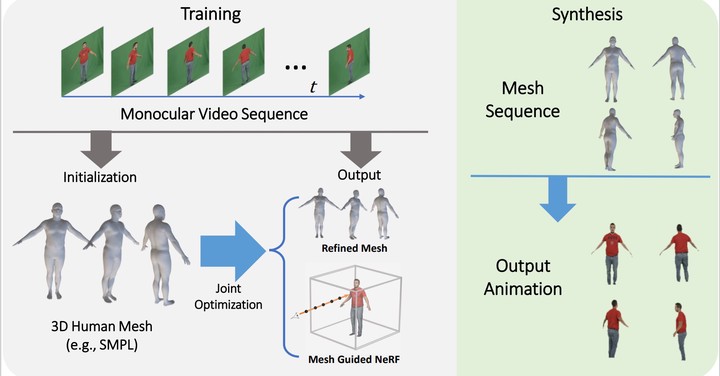
We present a novel paradigm of building an animatable 3D human representation from a monocular video input, such that it can be rendered in any unseen poses and views. Our method is based on a dynamic Neural Radiance Field (NeRF) rigged by a mesh-based parametric 3D human model serving as a geometry proxy. Previous methods usually rely on multi-view videos or accurate 3D geometry information as additional inputs; besides, most methods suffer from degraded quality when generalized to unseen poses.We identify that the key of generalization is a good input embedding for querying dynamic NeRF - A good input embedding should define an injective mapping in the full volumetric space, guided by surface mesh deformation under pose variation.Based on this observation, we propose to embed the input query with its relationship to local surface regions spanned by a set of geodesic nearest neighbors on mesh vertices. By including both position and relative distance information, our embedding defines a distance-preserved deformation mapping and generalizes well to unseen poses. To reduce the dependency on additional inputs, we first initialize per-frame 3D meshes using off-the-shelf tools and then propose a pipeline to jointly optimize NeRF and refine the initial mesh. Extensive experiments show our method can synthesize plausible human rendering results under unseen poses and views.